使用谷歌表格中的 IMPORTXML 函数从社交媒体获取数据并且导入表格。
在下面函数的例子中 A1 是引用单元格对应的链接。
Facebook 小组
小组名称
=IMPORTXML(A1, "//title")
小组横幅图
=IMAGE(IMPORTXML(A1, "//meta[@property='og:image']/@content"))
小组简介如果太长会显示不完整。
=IMPORTXML(A1, "//meta[@name='description']/@content")
小组 ID
=REGEXREPLACE(IMPORTXML(A1, "//meta[@property='al:android:url']/@content"), "[^\d]", "")

Facebook 专页/时间线
专页/时间线名称
=IMPORTXML(A1, "//title")
专页/时间线头像
=IMAGE(IMPORTXML(A1, "//meta[@property='og:image']/@content"))
专页点赞数和简介
=LAMBDA(desc, {
REGEXREPLACE(REGEXREPLACE(desc, " likes ·.+", ""), ".+\. ", ""),
REGEXREPLACE(desc, ".+talking about this. |.+were here. ", "")
})(SUBSTITUTE(IMPORTXML(A1, "//meta[@name='description']/@content"), CHAR(10), ""))
专页/时间线 ID
=REGEXREPLACE(IMPORTXML(A1, "//meta[@property='al:android:url']/@content"), "[^\d]", "")

Facebook 帖子
帖子内容
=IMPORTXML(A1, "//meta[@name='description']/@content")
帖子图片
=IMAGE(IMPORTXML(A1, "//meta[@property='og:image']/@content"))
帖子 ID
=REGEXREPLACE(REGEXREPLACE(IMPORTXML(A1, "//meta[@property='og:url']/@content"), ".+\D\/|\/$", ""), ".+\/", "")

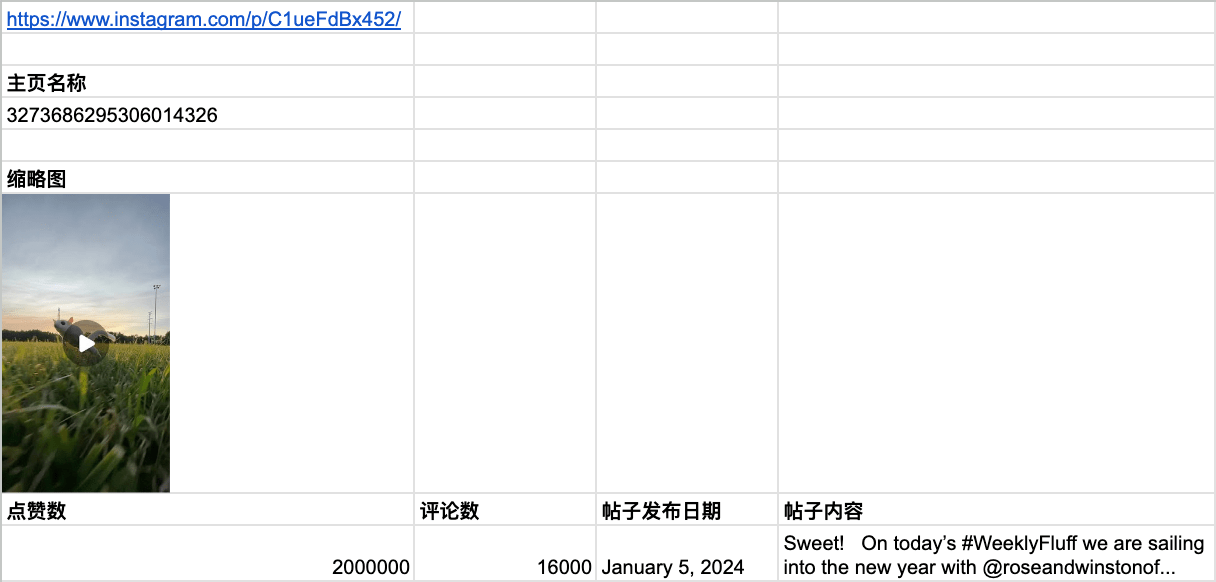
Instagram 主页
主页名称
=REGEXREPLACE(IMPORTXML(A1, "//title"), "..@.+", "")
主页粉丝数、关注数、帖子数
=LAMBDA(desc, {
LAMBDA(follower,
IFERROR(SWITCH(REGEXEXTRACT(follower, "K|M"), "K", REGEXREPLACE(follower, "\D","") * 1000, "M", REGEXREPLACE(follower, "\D","") * 1000000), follower)
)(REGEXREPLACE(desc, " Followers.+", "")),
REGEXREPLACE(desc, ".+Followers, | Following.+", ""),
REGEXREPLACE(desc, ".+, | Posts.+", "")
})(SUBSTITUTE(IMPORTXML(A1, "//meta[@name='description']/@content"), CHAR(10), ""))

Instagram 帖子
帖子 ID
=REGEXREPLACE(IMPORTXML(A1, "//meta[@property='al:ios:url']/@content"), "[^\d]", "")
帖子缩略图
=IMAGE(IMPORTXML(A1, "//meta[@property='og:image']/@content"))
点赞数、评论数、帖子发布日期、帖子内容
=LAMBDA(desc, {
LAMBDA(likes,
IFERROR(SWITCH(REGEXEXTRACT(likes, "K|M"), "K", REGEXREPLACE(likes, "\D","") * 1000, "M", REGEXREPLACE(likes, "\D","") * 1000000), likes)
)(REGEXREPLACE(desc, " likes.+", "")),
LAMBDA(comments,
IFERROR(SWITCH(REGEXEXTRACT(comments, "K|M"), "K", REGEXREPLACE(comments, "\D","") * 1000, "M", REGEXREPLACE(comments, "\D","") * 1000000), comments)
)(REGEXREPLACE(desc, ".+likes, | comments.+", "")),
REGEXREPLACE(desc, ".*?on |:.+", ""),
REGEXREPLACE(desc, ".*?: ""|""$", "")
})(SUBSTITUTE(IMPORTXML(A1, "//meta[@name='description']/@content"), CHAR(10), ""))
Instagram 标签
标签帖子数量
=LAMBDA(desc,
IFERROR(SWITCH(REGEXEXTRACT(desc, "K|M"), "K", REGEXREPLACE(desc, "\D","") * 1000, "M", REGEXREPLACE(desc, "\D","") * 1000000), desc)
)(REGEXREPLACE(A1, " posts.+", ""))
Tiktok
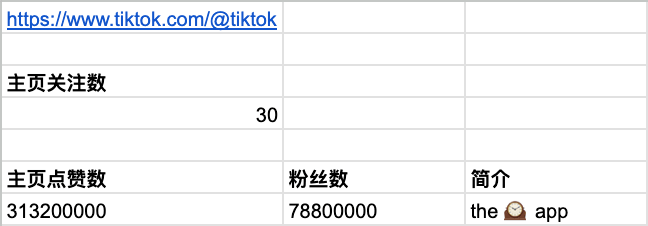
Tiktok 主页
主页关注数
=IMPORTXML(A1, "//strong[@data-e2e='following-count']")
主页点赞数、粉丝数、简介
=LAMBDA(json, {
REGEXREPLACE(json, "\n|.+LikeAction""},""userInteractionCount"":|}.+", ""),
REGEXREPLACE(json, "\n|.+FollowAction""},""userInteractionCount"":|}.+", ""),
SUBSTITUTE(REGEXREPLACE(json, "\n|.+description"":""|"",""alternateName.+", ""), "\n", CHAR(10))
})(SUBSTITUTE(IMPORTXML(A1, "//*[@id='Person']"), CHAR(10), ""))
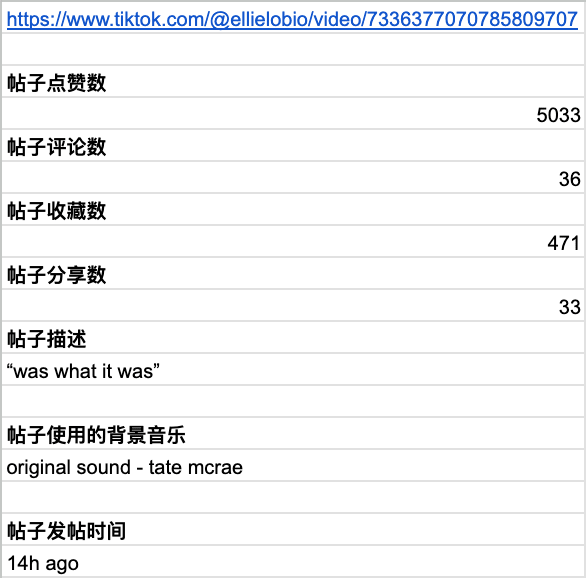
Tiktok 帖子
帖子点赞数
=IMPORTXML(A1, "//strong[@data-e2e='like-count']")
帖子评论数
=IMPORTXML(A1, "//strong[@data-e2e='comment-count']")
帖子收藏数
=IMPORTXML(A1, "//strong[@data-e2e='undefined-count']")
帖子分享数
=IMPORTXML(A1, "//strong[@data-e2e='share-count']")
帖子描述
=REGEXEXTRACT(SUBSTITUTE(IMPORTXML(A1, "//meta[@name='description']/@content"), CHAR(10), ""), "“.*?”")
帖子使用的背景音乐
=INDEX(IMPORTXML(A1, "//div[@class='tiktok-pvx3oa-DivMusicText epjbyn3']"), 1)
帖子发帖时间
=IMPORTXML(A1, "//span[@data-e2e='browser-nickname']/span[3]")
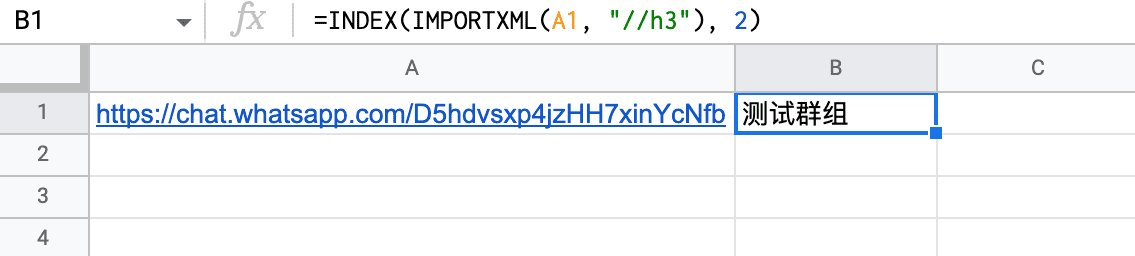
群组名称
=INDEX(IMPORTXML(A1, "//h3"), 2)
群组头像
=IMAGE(INDEX(IMPORTXML(A1, "//img/@src"), 3))
Telegram
Telegram 小组
小组名称
=IMPORTXML(A1, "//div[@class='tgme_page_title']")
小组成员数
=REGEXREPLACE(IMPORTXML(A1, "//div[@class='tgme_page_extra']"), "members.+|\D", "")
小组简介
=JOIN(CHAR(10), IMPORTXML(A1, "//div[@class='tgme_page_description']"))
小组头像
=IMAGE(IMPORTXML(A1, "//meta[@property='og:image']/@content"))

Telegram 频道
频道名称
=IMPORTXML(A1, "//div[@class='tgme_channel_info_header_title']")
频道头像
=IMAGE(IMPORTXML(A1, "//a[@class='tgme_header_link']//img//@src"))
频道关注数、图片数、链接数
=TRANSPOSE(IMPORTXML(A1, "//span[@class='counter_value']"))
频道描述
=JOIN(CHAR(10), IMPORTXML(A1, "//div[@class='tgme_channel_info_description']"))
频道近期帖文链接
=IMPORTXML(A1, "//div[@data-post]/@data-post")

YouTube
频道名称
=IMPORTXML(A1, "//meta[@name='twitter:title']/@content")
频道头像
=IMAGE(IMPORTXML(A1, "//meta[@property='og:image']/@content"))
频道简介
=IMPORTXML(A1, "//meta[@property='og:description']/@content")
视频缩略图
=IMAGE("https://img.youtube.com/vi/"®EXREPLACE(A1, ".+\.be\/|.+shorts\/|.+\.com\/watch\?v=|\?.+", "")&"/maxresdefault.jpg")
YouTube 的缩略图有 4 种分辨率,分别是:maxresdefault、hqdefault、sddefault、mqdefault。

主页粉丝数和关注数
=LAMBDA(info,
LAMBDA(fans, follower, {
IFERROR(SWITCH(REGEXEXTRACT(fans, "k|M"), "k", REGEXREPLACE(fans, "\D","") * 1000, "M", REGEXREPLACE(fans, "\D","") * 1000000), fans),
IFERROR(SWITCH(REGEXEXTRACT(follower, "k|M"), "k", REGEXREPLACE(follower, "\D","") * 1000, "M", REGEXREPLACE(follower, "\D","") * 1000000), follower)
})
(INDEX(info, 1, 1), INDEX(info, 2, 1))
)(IMPORTXML(A1, "//div[@class='tBJ dyH iFc sAJ O2T zDA IZT H2s']"))
主页简介
=SUBSTITUTE(IMPORTXML(A1, "//span[@class='tBJ dyH iFc sAJ O2T zDA IZT swG']"), CHAR(10), "")

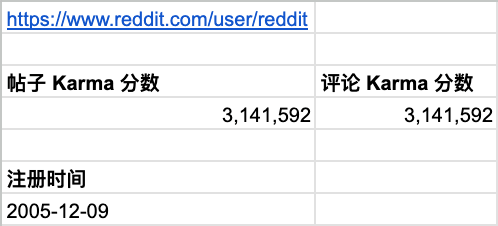
Reddit 主页
主页帖子和评论 Karma 分数
=TRANSPOSE(IMPORTXML(A1, "//span[@data-testid='karma-number']"))
注册时间
=REGEXREPLACE(IMPORTXML(A1, "//time[@data-testid='cake-day']/@datetime"), "T.+", "")
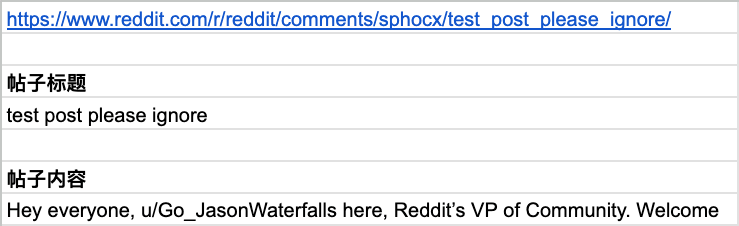
Reddit 帖子
帖子标题
=TRIM(JOIN("", IMPORTXML(A1, "//h1[@slot='title']")))
帖子内容
=TRIM(JOIN("", IMPORTXML(A1, "//div[@data-post-click-location='text-body']")))