比原生的方式更快的方法。
适用场景
有大量的数据,或者动态的数据需要跨表引用。
优化思路
将需要引用的数据拆分成多个异步执行,或者引用限定的范围。
实例一
有一个 30 万的数据需要跨表引用。如果是常规的方法直接引用
=IMPORTRANGE("SheetID", "A1:A300000")
大约需要 12 秒左右。
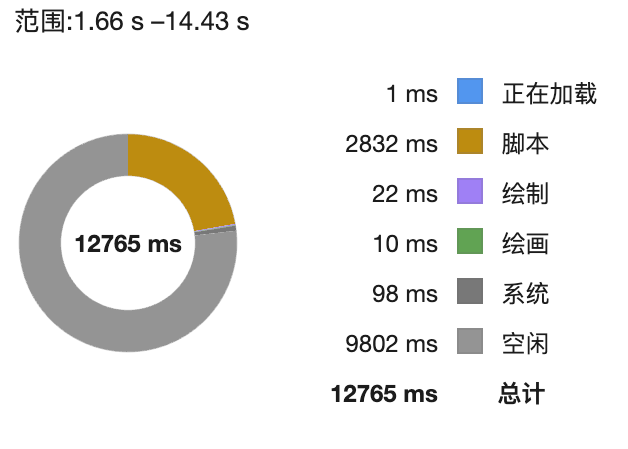
把 30 万的数据平均拆成 10 份,每个引用 3 万的数据,并且用数组执行。
={
IMPORTRANGE("SheetID", "A1:A30000");
IMPORTRANGE("SheetID", "A30001:A60000");
IMPORTRANGE("SheetID", "A60001:A90000");
IMPORTRANGE("SheetID", "A90001:A120000");
IMPORTRANGE("SheetID", "A120001:A150000");
IMPORTRANGE("SheetID", "A150001:A180000");
IMPORTRANGE("SheetID", "A180001:A210000");
IMPORTRANGE("SheetID", "A210001:A240000");
IMPORTRANGE("SheetID", "A240001:A270000");
IMPORTRANGE("SheetID", "A270001:A300000")
}
因为 IMPORTRANGE 函数是异步运行,所以并不会等待前面的结果计算完成后再运行下一个 IMPORTRANGE,而是在执行的过程中继续往下运行。大于需要 9 秒左右,相比常规的跨表引用速度要快。

实例二
有一个动态的内容需要跨表引用,数据会随时增加或者删减。因为数据长度的未知性,就需要引用更多的单元格或者引用一整列,确保增加数据的时候依然在引用的范围内,这样同时也会造成一个问题,会引用更多空白的单元格,造成没必要的性能消耗。
先使用 COUNTA 计算数据的长度,因为数据在第二行,所以需要将数据计算的结果再加一才能保持数据长度一致。

在另外一个工作表先用 IMPORTRANGE 引用数据的长度,也就是 COUNTA 计算的结果。然后引用范围从第二行开始,结束的行设置成计算好的数据长度。这样不管在数据源怎么变动数据,都可以将数据的长度同步到当前的表格,并且只引用需要的范围,这样要比一整列引用数据要小得多。





