无需购买服务器即可免费在线托管 ChatTTS。
ChatTTS 是专门为对话场景设计的文本转语音模型。
Colab 是一项托管的 Jupyter Notebook 服务。
部署项目
首先,需要有一个 Google 账号,然后新建一个 Colab 项目。
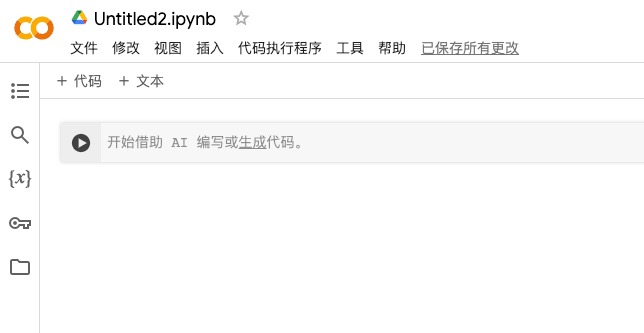
然后把下面的代码粘贴到项目中,点击「运行」按钮。
!git clone -q https://github.com/6drf21e/ChatTTS_colab
%cd ChatTTS_colab
!git clone -q https://github.com/2noise/ChatTTS
%cd ChatTTS
!git checkout -q f4c8329
%cd ..
!mv ChatTTS abc
!mv abc/ChatTTS ./ChatTTS
!pip install -q omegaconf vocos vector_quantize_pytorch gradio cn2an pypinyin openai jieba
!python webui_mix.py --share
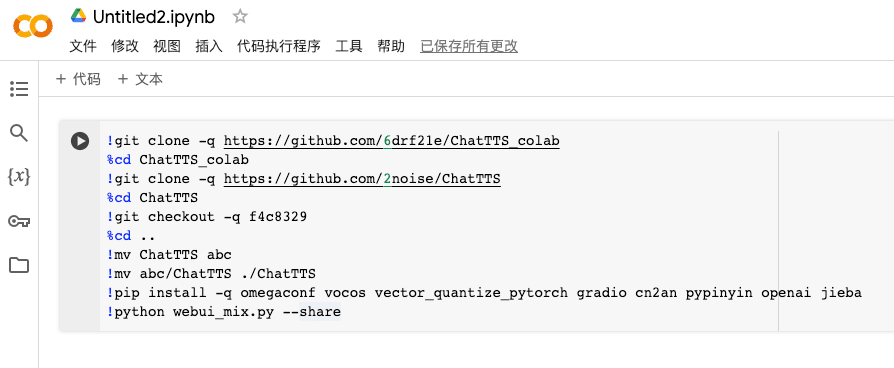
需要一会时间等待部署完成。当显示出下图内容的时候就代表部署完成了,打开 public URL 就可以使用了。
功能介绍
音色抽卡
使用测试文本和随机 seed 生成音频,选择适用的音频并且记录 seed 参数。这个功能的作用是挑选适合的音色,然后下次再通过文字转语音的时候使用相同的 seed 生成出一样的音色,但也有可能会存在一些差异。
测试文本建议简短一点,因为只是听音色,所以内容简短生成的速度会越快。seed 生成数量可以自定义,一批生成多个音频。
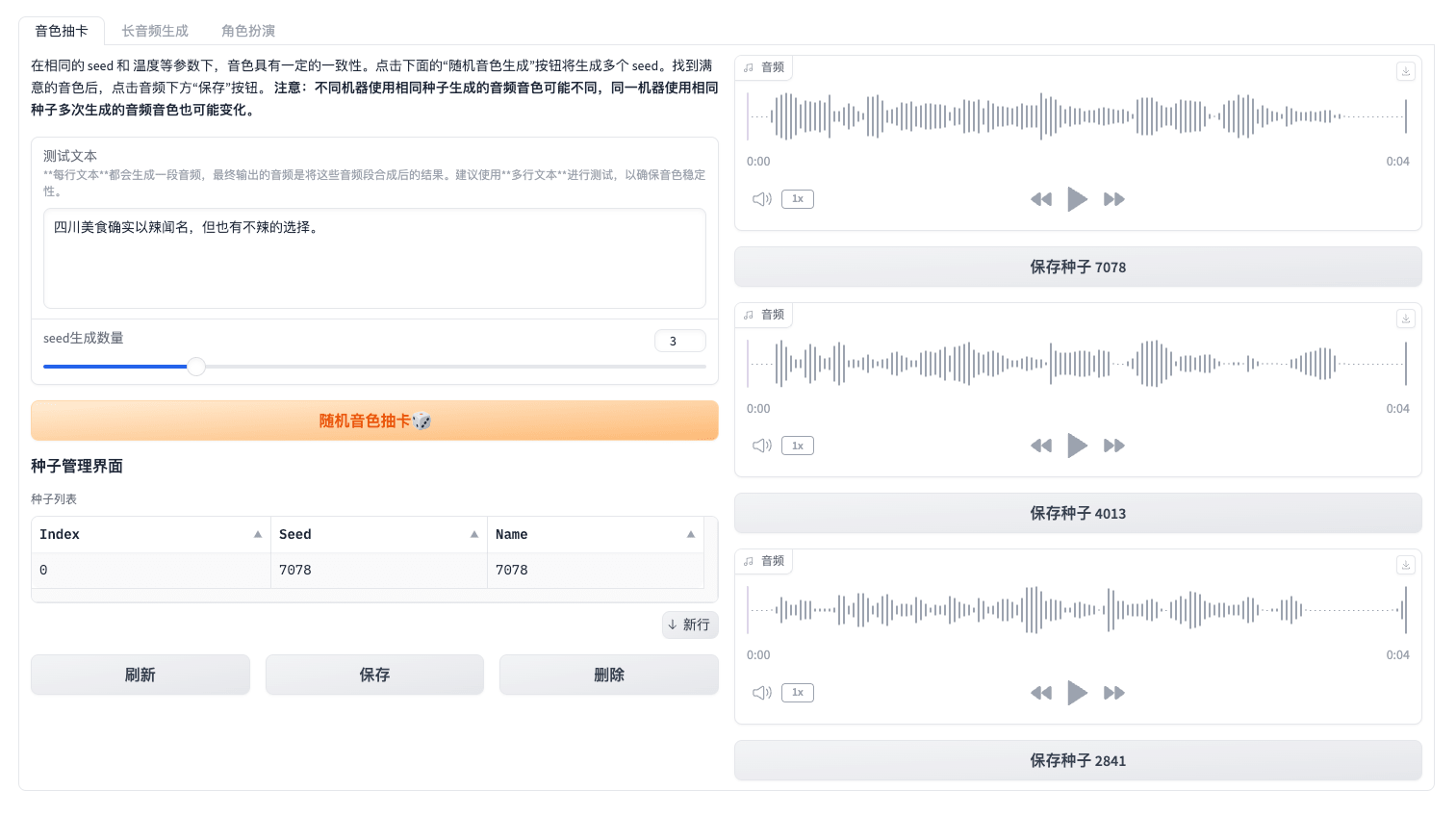
生成出音频后,在右侧可以点击播放键播放音频,也可以点击保存种子。
长音频生成
在左侧「朗读文本」中放入需要生成的文本。在文本中允许使用 prompt。在右侧可以自定义各种参数。
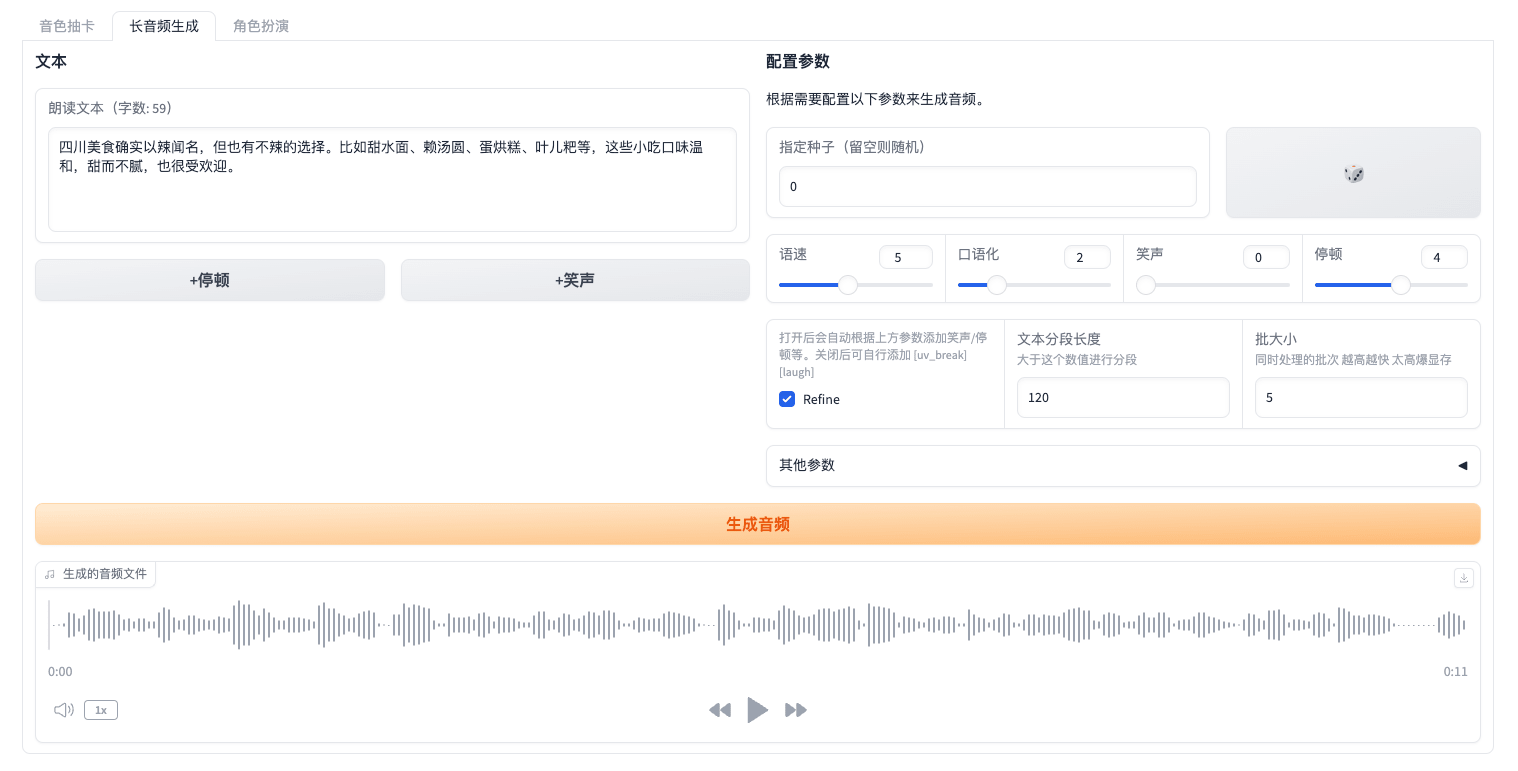
下面是参数介绍:
- 语速 (speed):数值越大,速度越快。
- 口语化 (oral):数值越大,添加的“就是”、“那么”之类的连接词越多。
- 笑声 (laugh):控制文本是否添加笑声,数值越大,笑声越多。
- 停顿 (break):控制文本是否添加停顿,数值越大,停顿越多。
- 温度 (temperate):控制音频情感波动,数值越大,波动性越大。
- top_P:控制音频情感相关性,数值越大,相关性越高。
- top_K:控制音频情感相似性,数值越大,相似性越高。




